Lexical Processing
Lexical Processing#
In any large text document (say, a hundred thousand words), the word frequencies follow Zipf distribution:
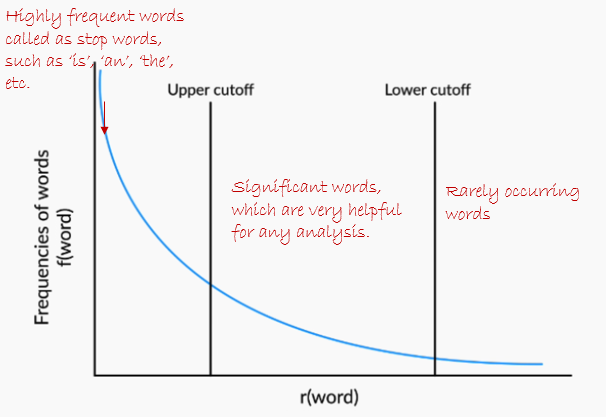
Zipf distribution#
Remove STOP words as they have high frequency and is most cases does not provide anything important
Tokenize or break the corpus by words, sentences, etc.
Canonicalisation or Reduce the words into their base forms:
Stemming: a rule-based technique that just chops off the suffix of a word to get its root form which is called the ‘stem’. For example converts driving, drive etc. to driv. But is not good for words like feet, drove etc.
Lemmatization: a more sophisticated technique, it doesn’t just chop off the suffix of a word. Instead, it takes an input word and searches for its base word by going recursively through all the variations of dictionary words. The base word, in this case, is called the ‘lemma’. It is more resource intensive and you need to pass the POS tag of the word along with the word to be lemmatized.
Phonetic Hashing: certain words which have different pronunciations in different languages. As a result, they end up being spelt differently. Example being Delhi and Dilli
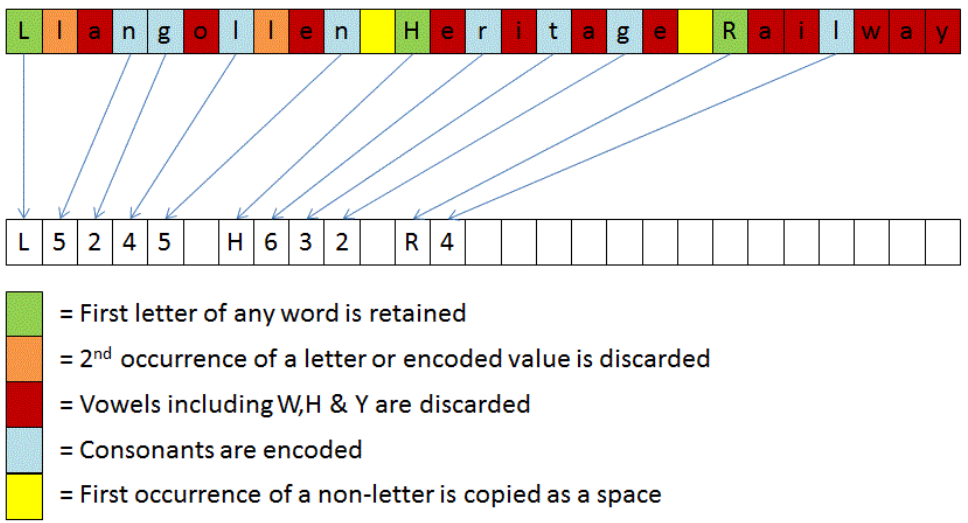
Edit Distance: Edit distance is a way of quantifying how dissimilar two strings are to one another by counting the minimum number of operations required to transform one string into the other. There are different methodologies for doing it, e.g. Hamming distance,Levenshtein distance, Jaro-Winkler etc.
Pointwise Mutual Information(PMI): Words like “Massachusetts Institute of Technology” are essentially one word but tokenization reduces these into individual words which is not desireable. PMI is used to determine whether this term should be represented by a single token or not.
Convert the data into tabular form:
Bag of Words(BoW): A table containing which word is present in which document, can be either count or binary
tf-idf: is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus. The tf–idf value increases proportionally to the number of times a word appears in the document and is offset by the number of documents in the corpus that contain the word, which helps to adjust for the fact that some words appear more frequently in general.
\( tf-idf = \frac{\text{freq of term 't' in doc 'd'}}{\text{total terms in 'd'}} * log \frac{\text{total number of docs}}{\text{total number of docs having term 't'}}\)