PyCaret
Contents
PyCaret#
PyCaret is an open-source, low-code machine learning library in Python that automates machine learning workflows. It is an end-to-end machine learning and model management tool that exponentially speeds up the experiment cycle and makes you more productive.
Compared with the other open-source machine learning libraries, PyCaret is an alternate low-code library that can be used to replace hundreds of lines of code with few lines only. This makes experiments exponentially fast and efficient. PyCaret is essentially a Python wrapper around several machine learning libraries and frameworks such as scikit-learn, XGBoost, LightGBM, CatBoost, spaCy, Optuna, Hyperopt, Ray, and a few more.
The link shared above has got detailed documentation and is an excellent resource to learn about PyCaret. Some common functions of PyCaret are discussed below.
Setup#
This function initializes the training environment and creates the transformation pipeline. Setup function must be called before executing any other function. It takes two mandatory parameters: data and target. All the other parameters are optional. Some of the things that can be done in setup are as follows:
Variables: Define which variables to numerical, categorical or which are the ones to be ignored
Missing Value Imputation
One Hot Encoding
Target Imbalance
Outlier Treatment
Scaling and Transformation
Feature Engineering and Selection
Train & Optimize#
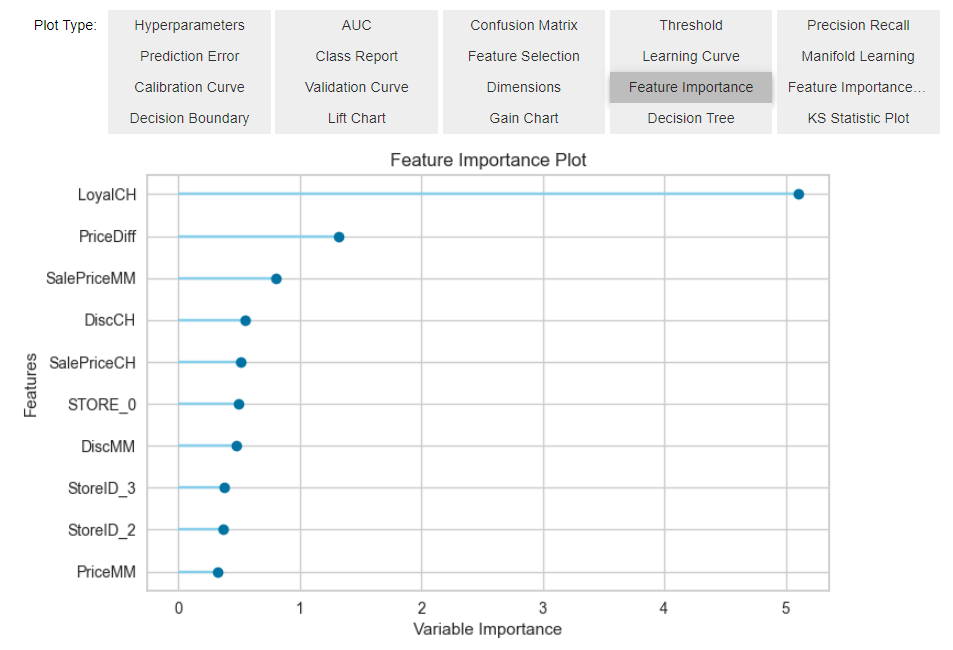
compare_models trains and evaluates the performance of all estimators available in the model library using cross-validation. Post model selection you can tune the model by optimizing prpbability threshold, stacking and ensembling models. PyCaret also provides an easy way to analyze your model by using the evaluate_model command. A single command which show out Hyperparameters, Plots, Feature importance and many things more.
The interpret_model command analyzes the predictions generated from a trained model. Most plots in this function are implemented based on the SHAP (Shapley Additive exPlanations).
Predict & Deploy#
predict_model function generates the output using a trained model. You can also get the raw probability scores for classification, set probability threshold and also monitor data drift. Post finalizing the model you can also easily deploy it in GCP, AWS and Azure.
As of now PyCaret supports Regression, Classification, Clustering, Anamoly detection, NLP, Association Rule Mining and Time series.