Sampling
Contents
Sampling#
Warning
This page is a work in progress
Oftentimes in practical machine learning problems there will be significant differences in the rarity of different classes of data being predicted. For example, when detecting cancer we can expect to have datasets with large numbers of false outcomes, and a relatively smaller number of true outcomes. Same with fraud analysis, the number of actual fraud cases will be much lower.
The overall performance of any model trained on such data will be constrained by its ability to predict rare points. In problems where these rare points are only equally important or perhaps less important than non-rare points, this constraint may only become significant in the later “tuning” stages of building the model. But in problems where the rare points are important, or even the point of the classifier (as in a cancer example), dealing with their scarcity is a first-order concern for the model builder.
Tangentially, note that the relative importance of performance on rare observations should inform your choice of error metric for the problem you are working on; the more important they are, the more your metric should penalize underperformance on them.
Several different techniques exist in the practice for dealing with imbalanced dataset. The most naive class of techniques is sampling: changing the data presented to the model by undersampling common classes, oversampling (duplicating) rare classes, or both.
Undersampling vs Oversampling#
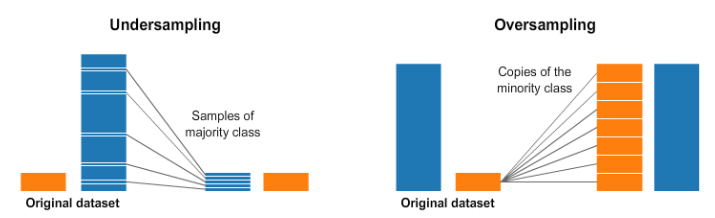
Undersampling means to get all of the classes to the same amount as the minority class or the one with the least amount of rows. To put this in an example: We have a dataset of 100 rows with three independent columns and one dependent feature, otherwise known as the class column. The class column has three labels: 1, 2, and 3. Label 1 has 39 instances, label 2 has 32 instances and label 3 has 29 instances. In order to apply undersampling to the aforementioned dataset, we would have to reduce label 1 and label 2 to the same amount of instances as label 3. Thus each label would have, in this particular case, 29 instances each.
In Oversampling we try to duplicate the other classes’ rows to be equal to that of the majority class.
However there is a caveat, over-sampling can cause overfitting and in case of under-sampling it can result in loss of information.