Anomaly Detection
Contents
Anomaly Detection#
An anomaly is something that differs from a norm: a deviation, an exception. In software engineering, by anomaly we understand a rare occurrence or event that doesn’t fit into the pattern, and, therefore, seems suspicious.
Types#
Global outliers: When a data point assumes a value that is far outside all the other data point value ranges in the dataset, it can be considered a global anomaly. In other words, it’s a rare event.
Contextual outliers: When an outlier is called contextual it means that its value doesn’t correspond with what we expect to observe for a similar data point in the same context. Contexts are usually temporal, and the same situation observed at different times can be not an outlier.
Collective outliers: Collective outliers are represented by a subset of data points that deviate from the normal behavior.
Methods of detecting Anamolies#
There are three categories of outlier detection, namely, supervised, semi-supervised, and unsupervised:
Supervised: Requires fully labeled training and testing datasets. An ordinary classifier is trained first and applied afterward. Here, the quality of the training dataset is very important and it is a lot of manual work involved since somebody needs to collect and label examples. Due to this mostly unsupervised methods are used in Anamoly detection.
Semi-supervised: Uses training and test datasets, whereas training data only consists of normal data without any outliers. A model of the normal class is learned and outliers can be detected afterward by deviating from that model.
Unsupervised: Does not require any labels; there is no distinction between a training and a test dataset Data is scored solely based on intrinsic properties of the dataset.
And three fundamental approaches to detect anomalies are based on:
By Density: Normal points occur in dense regions, while anomalies occur in sparse regions
By Distance: Normal point is close to its neighbors and anomaly is far from its neighbors
By Isolation: The term isolation means ‘separating an instance from the rest of the instances’. Since anomalies are ‘few and different’ and therefore they are more susceptible to isolation.
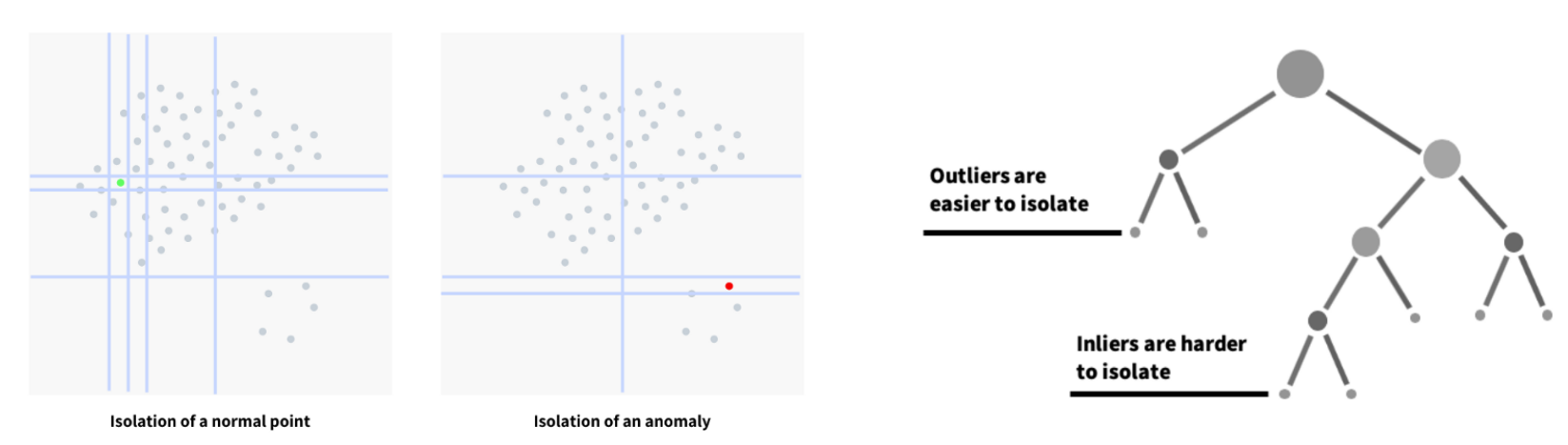
Isolation Forest#
Isolation Forest is an unsupervised anomaly detection algorithm that uses a random forest algorithm (decision trees) under the hood to detect outliers in the dataset. The algorithm tries to split or divide the data points such that each observation gets isolated from the others. Usually, the anomalies lie away from the cluster of data points, so it’s easier to isolate the anomalies compare to the regular data points.
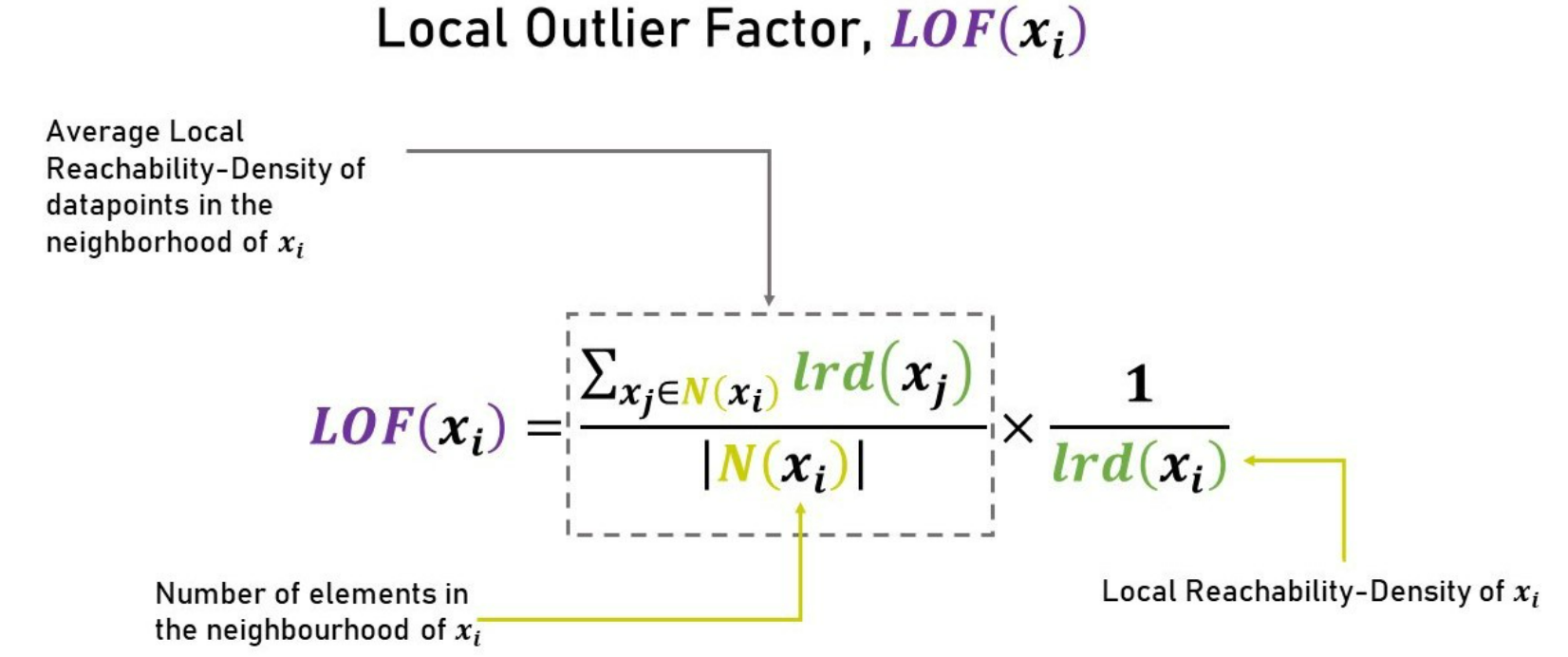
Local Outlier Factor#
It takes the density of data points into consideration to decide whether a point is an anomaly or not. The local outlier factor computes an anomaly score called anomaly score that measures how isolated the point is with respect to the surrounding neighborhood. It takes into account the local as well as the global density to compute the anomaly score.
Robust Covariance#
For gaussian independent features, simple statistical techniques can be employed to detect anomalies in the dataset. For a gaussian/normal distribution, the data points lying away from 3rd deviation can be considered as anomalies.
For a dataset having all the feature gaussian in nature, then the statistical approach can be generalized by defining an elliptical hypersphere that covers most of the regular data points, and the data points that lie away from the hypersphere can be considered as anomalies.
One Class SVM#
A regular SVM algorithm tries to find a hyperplane that best separates the two classes of data points. For one-class SVM where we have one class of data points, and the task is to predict a hypersphere that separates the cluster of data points from the anomalies.
One Class SVM (SGD)#
One-class SVM with SGD solves the linear One-Class SVM using Stochastic Gradient Descent. The implementation is meant to be used with a kernel approximation technique to obtain results similar to sklearn.svm.OneClassSVM which uses a Gaussian kernel by default.
Cluster-based Local Outlier Factor (CBLOF)#
The CBLOF calculates the outlier score based on cluster-based local outlier factor. An anomaly score is computed by the distance of each instance to its cluster center multiplied by the instances belonging to its cluster.
Histogram-based Outlier Detection (HBOS)#
HBOS assumes the feature independence and calculates the degree of anomalies by building histograms. In multivariate anomaly detection, a histogram for each single feature can be computed, scored individually and combined at the end.
KNN#
It is one of the simplest methods in anomaly detection. For a data point, its distance to its kth nearest neighbor could be viewed as the outlier score.
For Univariate Analysis Isolation Forest can be used to detect outliers that returns the anomaly score of each sample. Isolation Forest is a tree-based model. In these trees, partitions are created by first randomly selecting a feature and then selecting a random split value between the minimum and maximum value of the selected feature. In multivariate anomaly detection, outlier is a combined unusual score on at least two variables. For Multivariate Analysis multiple options are avaliable other than isolation forest:
Questions#
Problem: [AKAMAI] Anomaly in Univariate Dataset
Asked By - AKAMAI
If given a univariate dataset, how would you design a function to detect anomalies?
What if the data is bivariate?
Solution:
Reference: 📖Explanation
Anomaly detection is the process of identifying unexpected items or events in data sets, which differ from the norm. And anomaly detection is often applied on unlabeled data which is known as unsupervised anomaly detection. Anomaly detection has two basic assumptions:
Anomalies only occur very rarely in the data.
Their features differ from the normal instances significantly.
This is part is mentioned above too, for Univariate Analysis Isolation Forest can be used to detect outliers that returns the anomaly score of each sample. Isolation Forest is a tree-based model. In these trees, partitions are created by first randomly selecting a feature and then selecting a random split value between the minimum and maximum value of the selected feature.
In multivariate anomaly detection, outlier is a combined unusual score on at least two variables. For Multivariate Analysis multiple options are avaliable other than isolation forest:
The Cluster-based Local Outlier Factor (CBLOF)
Histogram-based Outlier Detection (HBOS)
KNN
An ensemble of these methods can be used to finalize the anamolies. Always visually investigate some of the anomalies.
Problem: Swamping VS Masking
What are the Swamping and Masking problems in Anomaly Detection?
Solution:
Since anomalies are rare events, making it very difficult to label them with high accuracy, swamping is the phenomenon of labeling normal events as anomalies.
When clustering algorithms are used, the data points belonging to different clusters get merged into one cluster, if the number of segments in the dataset is not known, this causes the outlier cluster to be merged to a cluster with normal data points. This causes the outliers to not be detected. This is defined as masking.
Problem: Uniform Distribution VS Normal Distribution
What are the differences in Anomalies for Uniform Distribution and Normal Distribution in One-Dimensional Data?
Solution:
Keep in mind how the Uniform and Normal Distribution looks like.
Uniform
When data is distributed uniformly over a finite range, the mean and standard deviation merely characterize the range of values.
One possible indication of anomalous behavior could be that a small neighborhood contains substantially fewer or more data points than expected from a uniform distribution.
Normal
A normal distribution follows the empirical rule, which states that 68%, 95%, and 99.7% of the values lie within one, two, and three standard deviations of the mean, respectively.
About 0.1% of the points are more than \(3 *\sigma\) (three standard deviations) away from the mean, hence, it is taken as the threshold and points beyond that distance from the mean are declared to be anomalous.
Problem: SVM VS Logistic Regression
Compare SVM and Logistic Regression in handling outliers
Solution:
For Logistic Regression, outliers can have an unusually large effect on the estimate of logistic regression coefficients. It will find a linear boundary if it exists to accommodate the outliers. To solve the problem of outliers, sometimes a sigmoid function is used in logistic regression.
For SVM, outliers can make the decision boundary deviate severely from the optimal hyperplane. One way for SVM to get around the problem is to intrduce slack variables. There is a penalty involved with using slack variables, and how SVM handles outliers depends on how this penalty is imposed.
Problem: Outlier VS Novelty
Explain the difference between Outlier Detection vs Novelty Detection
Solution:
The training data contains outliers which are defined as observations that are far from the others. Outlier detection estimators thus try to fit the regions where the training data is the most concentrated, ignoring the deviant observations.
The training data is not polluted by outliers and we are interested in detecting whether a new observation is an outlier. In this context an outlier is also called a novelty.
Outlier detection and novelty detection are both used for anomaly detection, where one is interested in detecting abnormal or unusual observations. Outlier detection is then also known as unsupervised anomaly detection and novelty detection as semi-supervised anomaly detection.
In the context of outlier detection, the outliers/anomalies cannot form a dense cluster as available estimators assume that the outliers/anomalies are located in low density regions. On the contrary, in the context of novelty detection, novelties/anomalies can form a dense cluster as long as they are in a low density region of the training data, considered as normal in this context.
Problem: Out of Distribution VS Anomaly
What is the difference between Out of Distribution and Anomaly Detection?
Solution:
Out of distribution (OOD) data refers to data that was collected at a different time, and possibly under different conditions or in a different environment than the data collected to create the model. It can be said that the data is from a different distribution.
After the out of distribution data is collected, the model can perform either Novelty detection or Anomaly detection.
Novelty data is the data that is in-distribution. Novelty detection checks whether the new data is in-distribution or not.
Anomaly detection is used to test the data to see if it is different than what the model was trained on.
Problem: Resolution-Based Outlier Detection
What is a Resolution-Based Outlier Detection?
Solution:
The resolution-based outlier detection is an approach to address the problem of parameter value determination by measuring the outlierness of an observation \(p ∈ D\) at different resolutions, and aggregating the results.
In this algorithm, at the highest resolution, all observations are isolated points and thus considered to be outliers whereas at the lowest resolution all observations belong to one cluster and none is considered to be an outlier.
As the resolution decreases from its highest value to the lowest value some observations in D begin to form clusters leaving other observations out of the clusters, and this phenomenon is captured in the resolution based outlier detection approach.
Problem: Change Detection
What is the Change Detection problem in Anomaly Detection?
Solution:
Change detection or change point detection tries to identify times when the probability distribution of a time series changes.
Change detection is generally used to detect anomalous behavior.
Change point detection is great for the following cases:
Detecting anomalous sequences/states in a time series.
Detecting the average velocity of unique states in a time series.
Detecting a sudden change in a time series state in real-time.
Problem: Drawbacks of Density Based Method
Can you tell some shortcomings of density based anomaly detection methods?
Solution:
Density-based outlier detection method investigates the density of an object and that of its neighbors. Here, an object is identified as an outlier if its density is relatively much lower than that of its neighbors. Many real-world data sets demonstrate a more complex structure, where objects may be considered outliers with respect to their local neighborhoods, rather than with respect to the global data distribution.
Problem: Distance based Outlier detection
Explain Distance based Outlier detection methods?
Solution:
A distance-based outlier detection method consults the neighborhood of an object, which is defined by a given radius. An object is then considered an outlier if its neighborhood does not have enough other points. This is termed as Distance-Based Outlier Detection Methods.
Distance-Based Methods usually depend on a Multi-dimensional Index, Which is used to retrieve the neighborhood of each object to see if it contains sufficient points. If there are insufficient points, then the object is termed an outlier.
Distance-Based methods scale better to multi-dimensional space and can be computed more efficiently than the statistical-based method. Identifying Distance-based outliers is an important and useful data mining activity. The main disadvantage of distance-based methods is that distance-based outlier detection is based on a single value of a custom parameter. This can cause significant problems if the dataset contains both dense and sparse regions.
Outlier detection methods can be categorized according to whether the sample of data for analysis is given with expert-provided labels that can be used to build an outlier detection model. In this case, the detection methods are supervised, semi-supervised, or unsupervised. Alternatively, outlier detection methods may be organized according to their assumptions regarding normal objects versus outliers. This categorization includes statistical methods, proximity-based methods, and clustering-based methods.
Algorithms For Mining Distance-Based Outliers:
Index-based algorithm: The index-based algorithm facilitates multidimensional indexing structures, including R-trees or \(k-d\) trees, to search for neighbors of each object \(o\) inside radius \(d\) around that object. Once \(K (K = N(1-p))\) neighbors of object \(o\) are discovered, it is accessible that \(o\) is not an outlier. This algorithm has the lowest case complexity of \(O (k * n^2)\), where \(k\) is the dimensionality, and \(n\) is the number of objects in the data set.
Nested-loop algorithm: The nested loop algorithm has the same evaluation complexity as the index-based algorithm but avoids building index structures and minimizes the amount of I/O. It splits the memory buffer in half and puts the data into several logical blocks.
Cell-based algorithm: It avoids the \(O(n^2)\) computational complexity and develops a cell-based algorithm for memory-resident datasets. Its complexity is \(O(c*k + n)\), where \(c\) is a constant based on the number of cells and \(k\) is the dimension.
Problem: Dictionary learning in Anamoly detection
Can you explain Dictionary learning in Anamoly detection?
Solution:
Dictionary learning generalizes the assumption that “typical” data points inhabit a low-dimensional subspace of the ambient space by proposing that points may all lie in the union of many very low-dimensional subspaces. Specifically, using sparse coding techniques, dictionary learning represents each data point as a linear combination of only a few basis elements, ie. dictionary atoms. Since each data point is closely related to its corresponding atoms, points using the same atoms are presumably semantically related, naturally grouping the data. This suggests that anomalous data will exhibit at least one of three properties:
Anomalous data will not be well represented by a learned dictionary as long as the dictionary is constrained to a sufficiently small number of atoms. Therefore, anomalies can be identified as having large residuals.
The learned dictionary will be more influenced by anomalies than by data points that follow the greater trend, since anomalies will be much farther from the union of the spans of small subsets of the dictionary than from the span of the entire dictionary. That is, anomalous data will have high leverage on the model relative to “typical” data.
If the dictionary contains a sufficiently large number of atoms or the anomalies occur frequently, these data points will fit the model well but will use “rare” basis atoms. These atoms are typically not used by regular data and are included in the learned model primarily to “accommodate” the anomalous data. Alternatively, typical basis elements may be used in atypical combinations to represent anomalous points.
Problem: Autoencoder in Anamoly Detection
How are Autoencoders used in Anamoly Detection?
Solution:
One of the predominant use cases of the Autoencoder is anomaly detection. Think about cases like IoT devices, sensors in CPU, and memory devices which work very nicely as per functions. Still, when we collect their fault data, we have majority positive classes and significantly less percentage of minority class data, also known as imbalance data. Sometimes it is tough to label the data or expensive labelling the data, so we know the expected behaviour of data.
We pass Autoencoder with majority classes(normal data). The training objective is to minimize the reconstruction error, and the training objective is to minimize this. as training progresses, the model weights for the encoder and decoder are updated. The encoder is a downsampler, and the decoder is an upsampler. Encoder and decoder can be ANN, CNN, or LSTM neural network.
What AutoEncoder does? It learns the reconstruction function that works with normal data, and we can use this Model for anomaly detection. We get low reconstruction error for normal data and high for abnormal data(minority class).